Quick Start Guide
This guide helps you get started with the Geonode Scraper API in a few minutes.
Get Your API Key
- Sign in to your Geonode account.
- Open the Dashboard.
- Navigate to the API Keys section.
- Create or copy an existing API key.
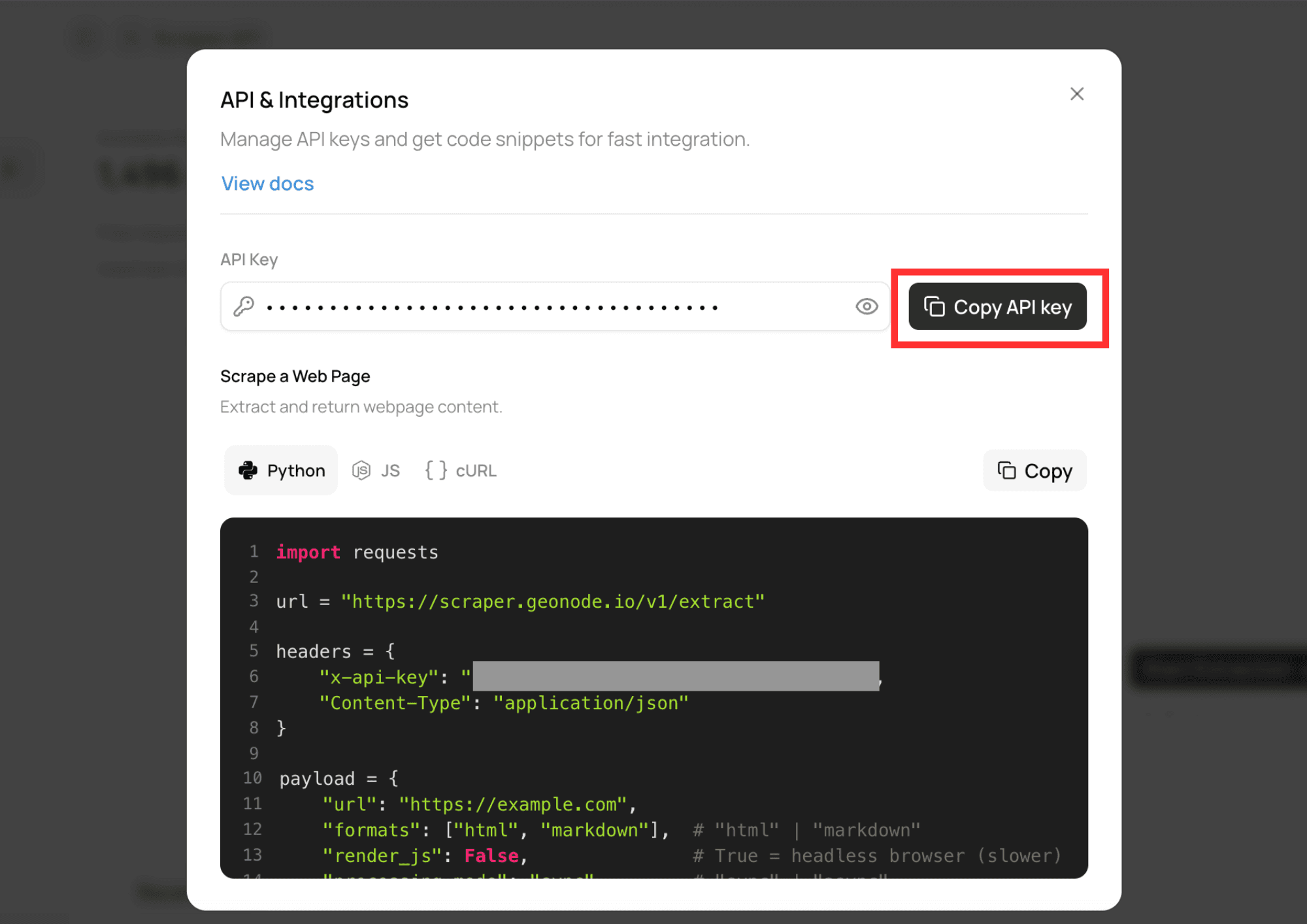
Authentication
All Scraper API requests require the X-Api-Key header.
curl -H "X-Api-Key: YOUR_API_KEY"Replace YOUR_API_KEY with your actual API key.
Choose an API
| API | Use When |
|---|---|
| Extraction | You want to extract content from one or more webpages |
| Batch | You have multiple URLs to process in a single job |
| Crawl | You want to discover and extract pages across a website |
| Webhooks | You want notifications when jobs complete |
Next Steps
Choose the API that matches your use case and follow the guides in that section.